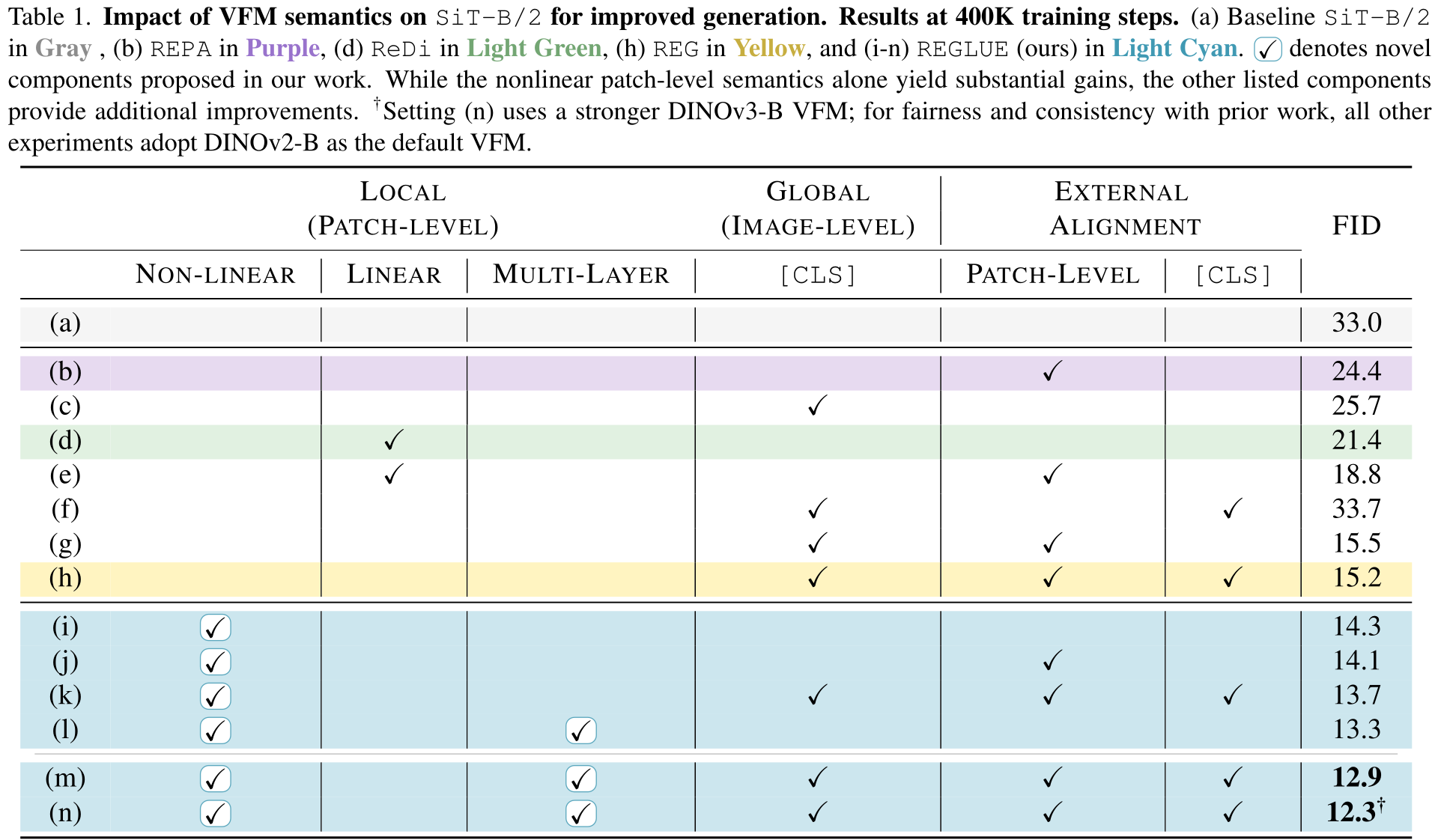
Abstract
Latent diffusion models (LDMs) achieve state-of-the-art image synthesis, yet their reconstruction-style denoising ob- jective provides only indirect semantic supervision: high- level semantics emerge slowly, requiring longer training and limiting sample quality. Recent works inject seman- tics from Vision Foundation Models (VFMs) either exter- nally via representation alignment or internally by jointly modeling only a narrow slice of VFM features inside the diffusion process, under-utilizing the rich, nonlinear, multi- layer spatial semantics available. We introduce REGLUE (Representation Entanglement with Global-Local Unified Encoding), a unified latent dif- fusion framework that jointly models (i) VAE image la- tents, (ii) compact local (patch-level) VFM semantics, and (iii) a global (image-level) [CLS] token within a single SiT backbone. A lightweight convolutional semantic com- pressor nonlinearly aggregates multi-layer VFM features into a low-dimensional, spatially structured representation, which is entangled with the VAE latents in the diffusion pro- cess. An external alignment loss further regularizes inter- nal representations toward frozen VFM targets. On Ima- geNet 256x256, REGLUE consistently improves FID and accelerates convergence over SiT-B/2 and SiT-XL/2 base- lines, as well as over REPA, ReDi, and REG. Extensive experiments show that (a) spatial VFM semantics are cru- cial, (b) non-linear compression is key to unlocking their full benefit, and (c) global tokens and external alignment act as complementary, lightweight enhancements within our global-local-latent joint modeling framework. The code is available at https://github.com/giorgospets/reglue
More Semantics are needed! ➕
Existing joint modeling and external alignment approaches (e.g., REPA, REG) inject only a “narrow slice” of Vision Foundation Model (VFM) features into diffusion. We argue that richer semantics are required to unlock the full potential of latent diffusion models.
Key design choice 🧩 Compact spatial semantics matter!
To leverage VFMs effectively, diffusion should jointly model VAE latents with multi-layer VFM spatial (patch-level) semantics, via a compact, non-linearly compressed representation.
Main Insight 💡
Jointly modeling compressed patch-level semantics ➕ VAE latents provides spatial guidance and yields larger gains than alignment-only (REPA) or global-only (REG). Alignment loss and a global [CLS] token stay complementary, orthogonal signals.
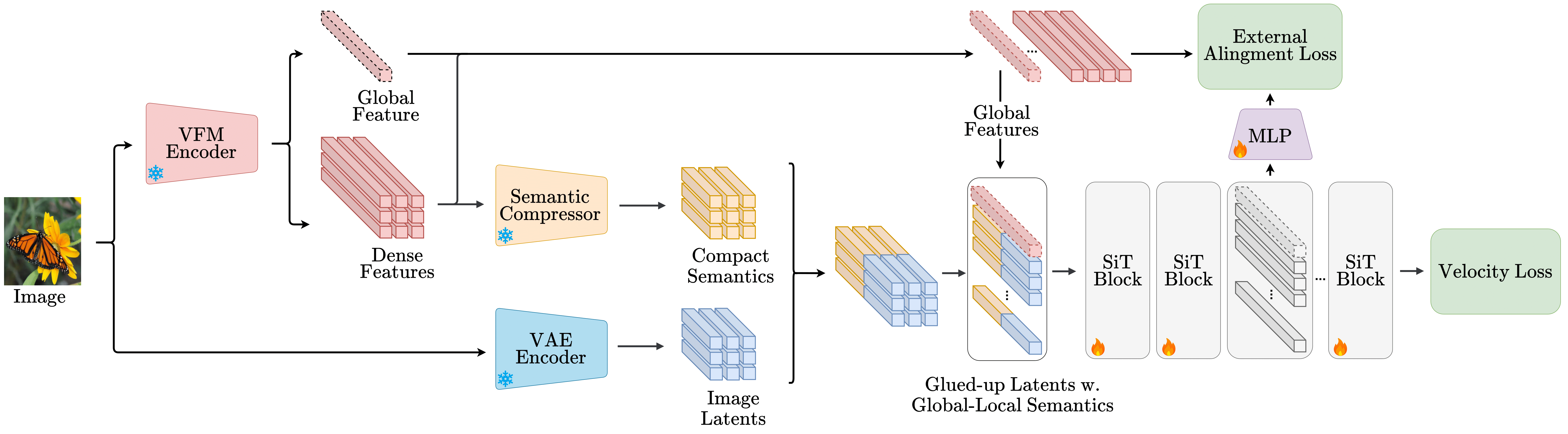
Our Method 🧠
REGLUE puts these into one unified model and jointly models:
1️⃣ VAE latents (pixels)
2️⃣ Local semantics (compressed patch features)
3️⃣ Global [CLS] (concept)
➕ Alignment loss as a complementary auxiliary boost.
Non Linear Compression Matters 💎
Linear PCA can limit patch-level semantics (e.g., ReDi). We introduce a lightweight non-linear semantic compressor that aggregates multi-layer VFM features into a compact, semantics-preserving space, boosting quality (21.4 → 13.3 FID).

The representations from the last four layers of the vision foundation model (VFM) encoder are concatenated and passed to the compression model, which projects them into a compact 16-channel semantic representation. In our default configuration, the compressor maps the dense concatenated VFM features through an input layer Conv2D(3072, 256), a middle ResidualBlock(256, 256), and an output layer Conv2D(256, 16), where 256 is the hidden dimensionality. The semantic de-compressor then reconstructs the compact semantics back to their original dimensionality. The model is trained using an MSE loss between the dense concatenated features and their reconstructed counterparts.
Local > Global Semantics 🧩
Our analysis shows that jointly modeling with patch-level semantics drives most gains. The global [CLS] helps, but fine-grained spatial features deliver a significantly larger FID improvement, highlighting the importance of local structure for diffusion.
Alignment effects⚓
External alignment complements joint modeling, but its benefits depend on the signal. Local alignment yields consistent gains, whereas global-only alignment can degrade performance. Spatial joint modeling remains the primary driver.
Faster convergence 🔥
REGLUE with SiT-XL/2 matches 1M-step SOTA performance in just 700k iterations (~30% fewer steps) and improves FID across training budgets. Using the SiT-B/2 diffusion model, REGLUE consistently improves FID in both conditional and unconditional generation, achieving 12.9 and 28.7 at 400K iterations, respectively, outperforming REPA, ReDi, and REG.

Comparable Results ImageNet 256x256 generation without classifier-free guidance (CFG). Left: SiT-B/2 performance in both conditional and unconditional generation. Right: SiT-XL/2 performance in conditional generation. Across scales and settings, REGLUE consistently achieves faster convergence and lower FID. We report parameter count, iterations, and FID.
Semantic Preservation under compression
We evaluate how well compressed patch-level features retain VFM semantics via attentive probing accuracy on ImageNet and semantic segmentation mIoU on Cityscapes vs generative quality (FID).
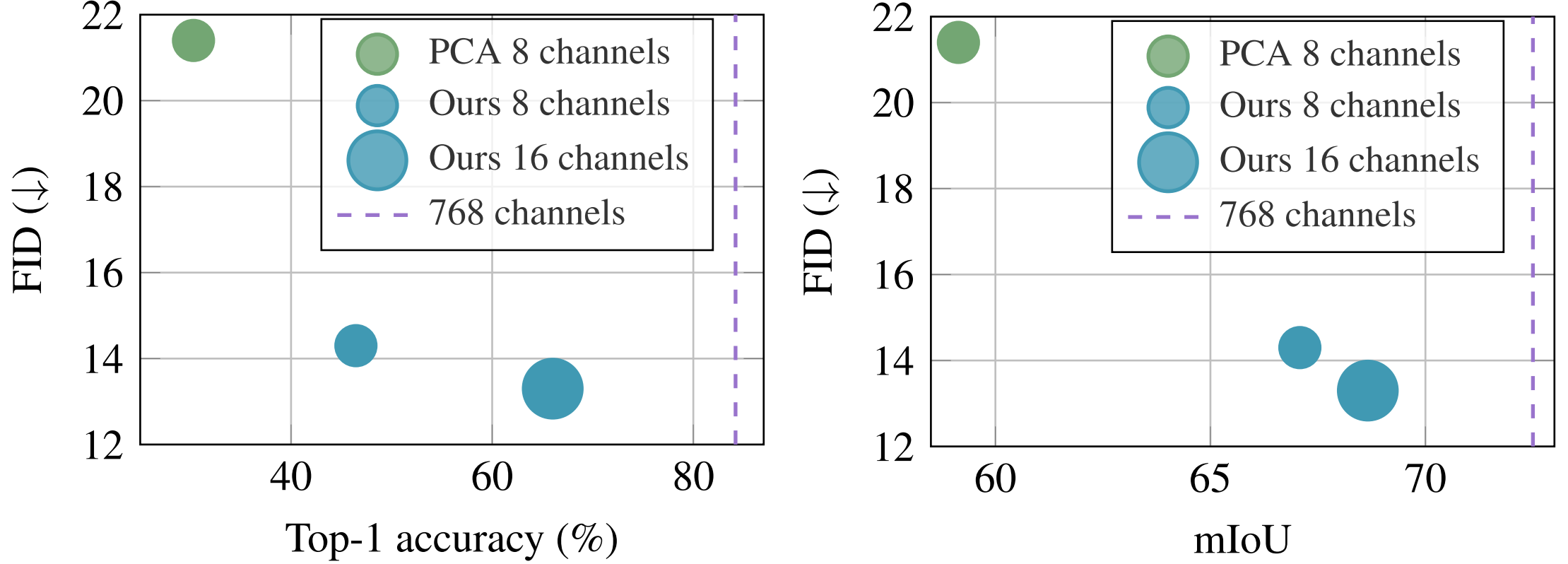
Points compare downstream semantic performance of frozen, compressed DINOv2 features (x-axis) with generation quality (ImageNet FID) of the corresponding SiT-B trained on both VAE latents and the compressed features (y-axis). Left: ImageNet attentive-probing top-1 accuracy vs. FID. Right: Cityscapes mIoU (DPT head on frozen features) vs. ImageNet FID.
Summary 🏁
REGLUE shows that the way we leverage VFM semantics matters for diffusion. Combining compact local semantics with global context yields faster convergence and state-of-the-art image generation.
BibTeX
@article{petsangourakis2025reglue,
title={REGLUE Your Latents with Global and Local Semantics for Entangled Diffusion},
author={Petsangourakis Giorgos, Sgouropoulos Christos, Psomas Bill, Giannakopoulos Theodoros, Sfikas Giorgos, Kakogeorgiou Ioannis},
journal={arXiv preprint arXiv:2512.16636},
year={2025}
}